Cleaning for Data Science
Modern data science applications rely heavily on machine learning models. We seek to understand and optimize data cleaning in this new setting.
ActiveClean
Databases can be corrupted with various errors such as missing, incorrect, or inconsistent values. Increasingly, modern data analysis pipelines involve Machine Learning, and the effects of dirty data can be difficult to debug. Dirty data is often sparse, and naive sampling solutions are not suited for high-dimensional models. The following figures show how data cleaning can degrade the machine learning model.
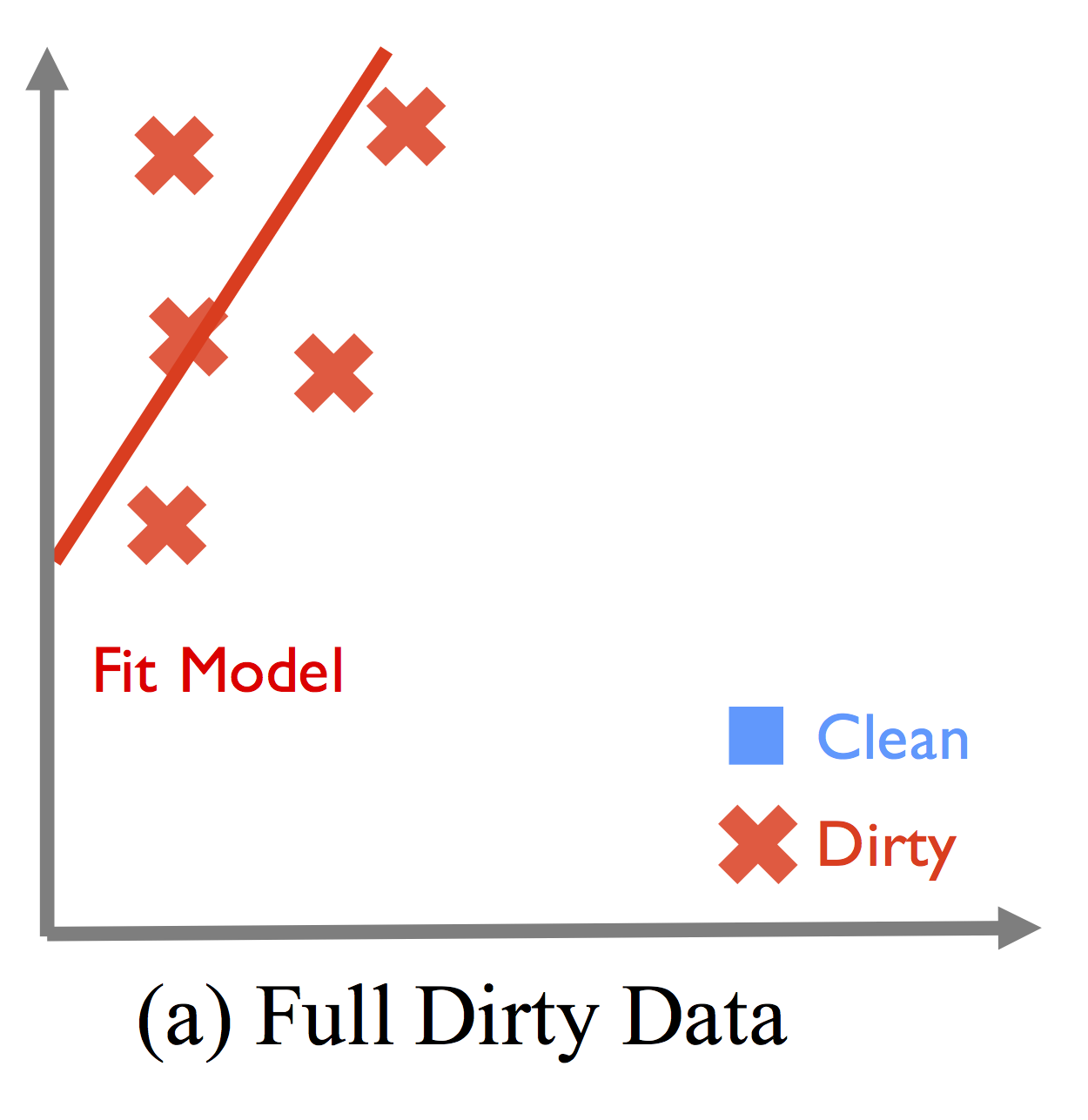
Shows how systematic corruption of data (from circles to crosses) can lead to a shifted, incorrect model.
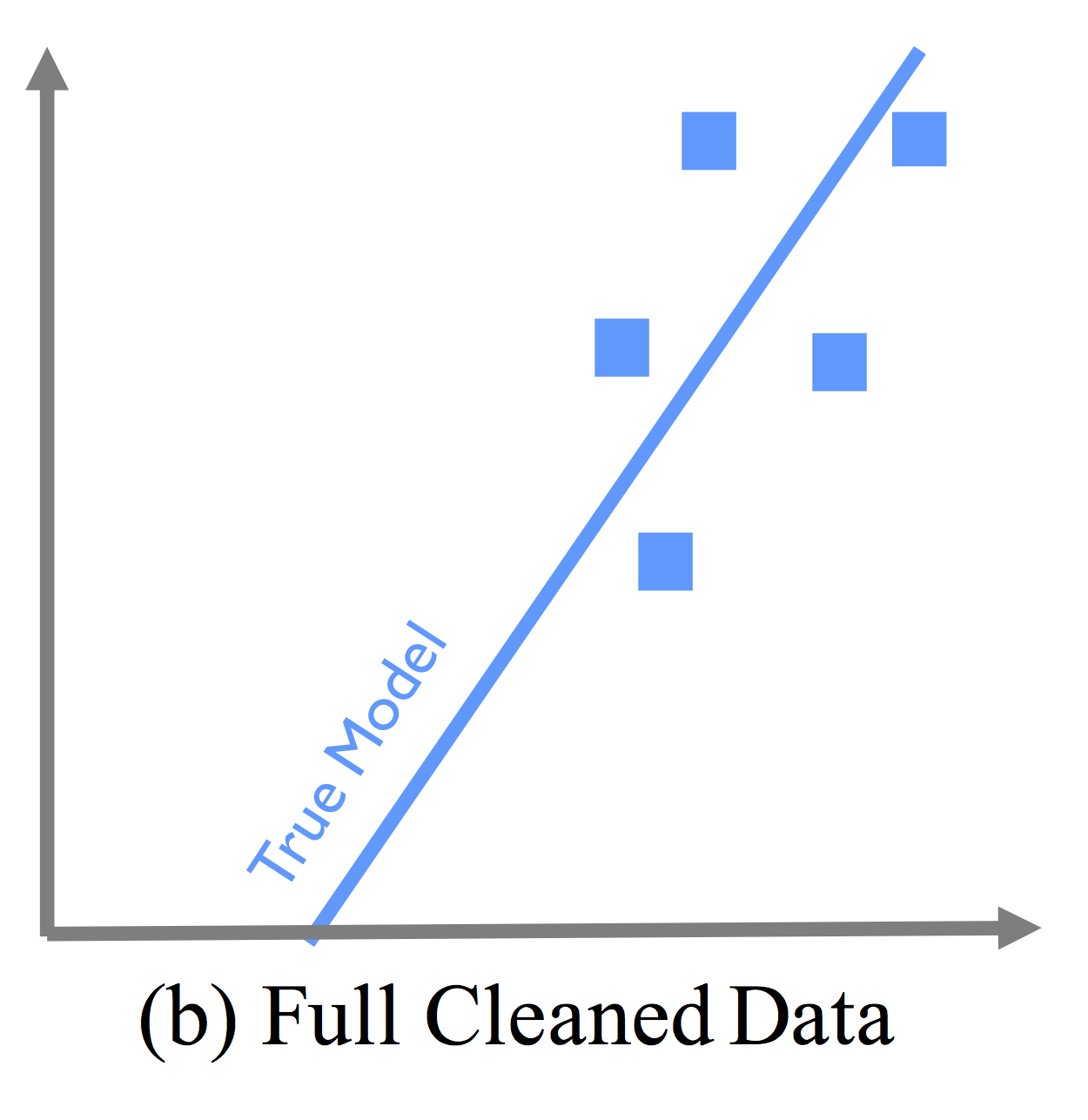
Illustrates the true model if the full dataset were cleaned.
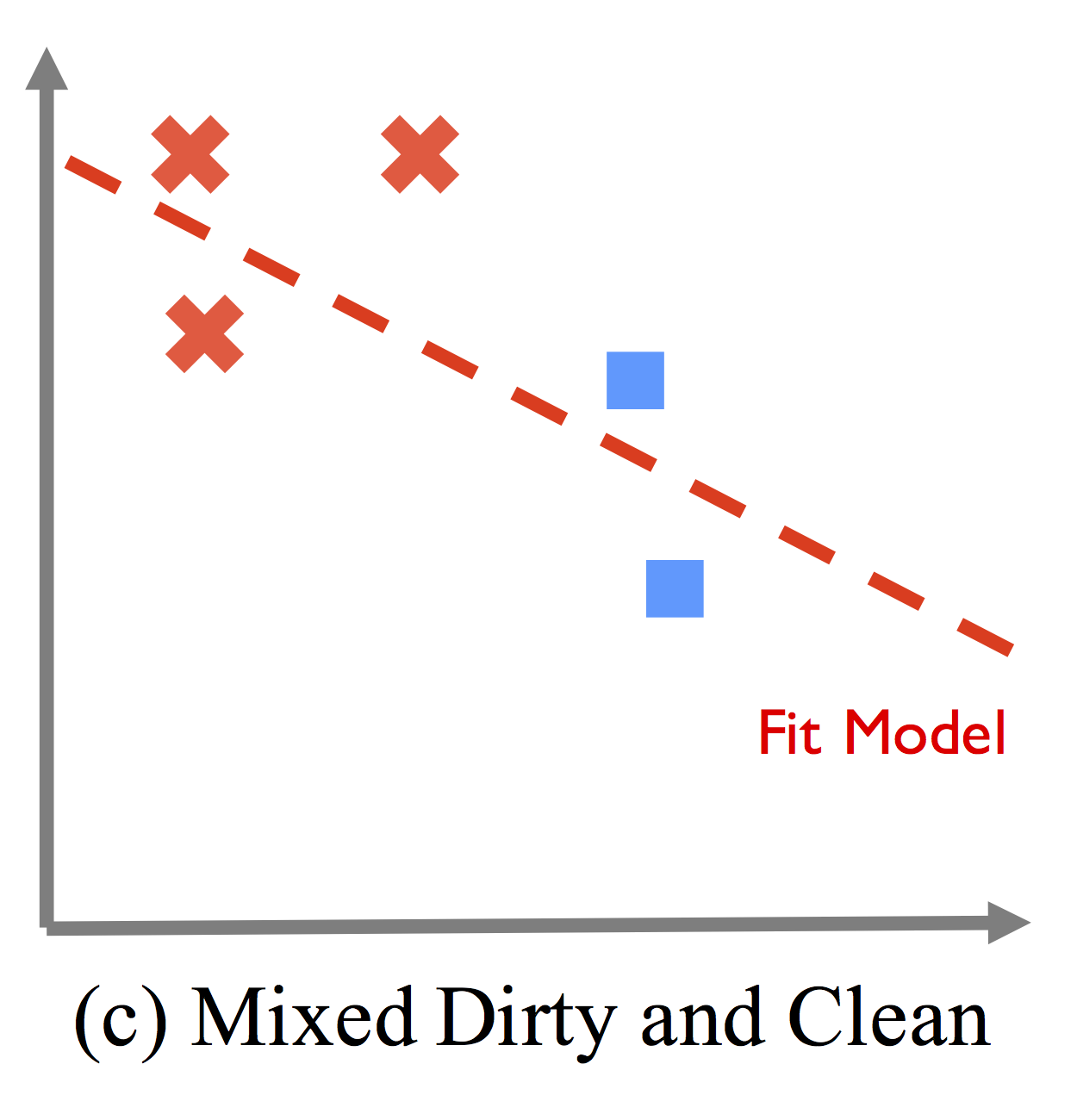
Shows how combining two cleaned records (blue) with the dirty records leads to a worse model than no cleaning.
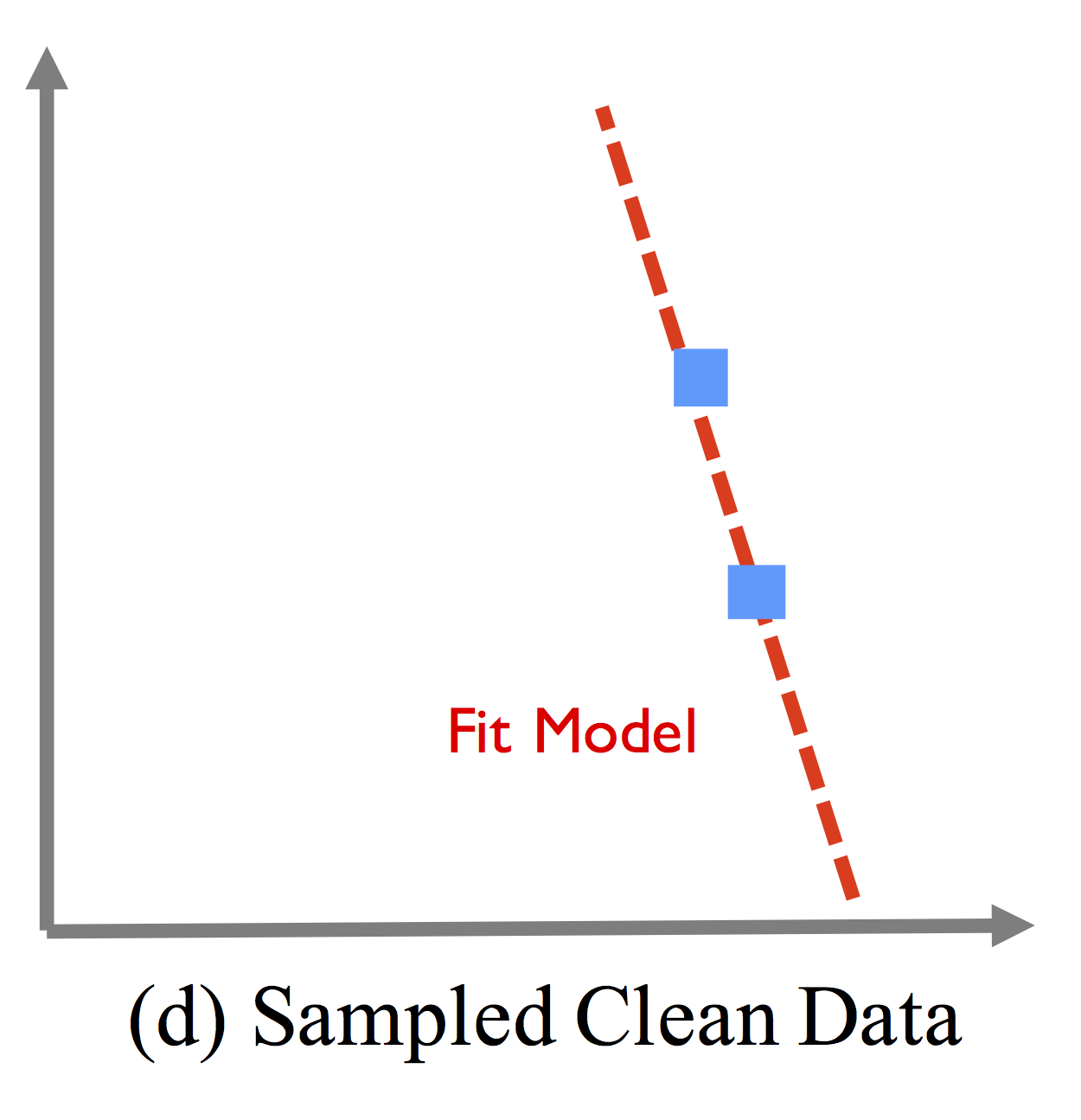
Shows how only using the two cleaned records can also result in a worse model due to sampling error.
ActiveClean is an iterative cleaning framework that can correctly retrain the machine learning model when data is cleaned, and provides a set of optimizations to select the best data to be cleaned. In this way, you only need to clean a small subset of the data in order to produce a model similar to if the full dataset were cleaned.
Code
The ActiveClean codebase is written in Python and includes the core ActiveClean algorithm, a data cleaning benchmark, and (in the future), an dirty data detector:
The Data Cleaning Benchmark automatically injects data errors into your datasets to test the robustness of your machine learning models to data errors. It can be installed using pip:
pip install cleaningbenchmark
To reproduce our results and run the code, simply download the files in the following link and run the python file using:
python activeclean_sklearn.py
The script is quite simple, so you can read it to see everything in action.
Publications



News
Contact
Please contact Sanjay Krishnan or Eugene Wu with any questions. We'd love to learn about your data cleaning pipeline and technical issues related to data cleaning for machine learning!
Collaborators
ActiveClean is a collaboration between the WuLab at Columbia University, the AMPLab at University of California, Berkeley, and Jiannan Wang at Simon Fraser University.